前言
这篇文章是一次常态化渗透测试的思路总结,不是复现过程,图也比较少,主要记录的是整个测试的思路流程。测试时间大概是一天。
一、初始资产侦察
到手的资产是一些外网域名和内网 IP,由于某些原因内网部分没法直接访问,就先把精力放在外网上。
随便打开了几个,看了一眼大致情况:
一个有登录框,但有评审入口可以直接跳过登录
一个正常网页
一个纯登录框,看起来好像能注册
大差不差,先从第一个开始测。
二、登录框测试
说实话不是很想测登录框这种东西,大概看了看,就没打算抓包仔细测了。
登录方式有两种:账号密码 和 手机号。
随便用了几个弱口令,比如admin、admin123,登录失败,发现验证码没有刷新,这是个可以记一下的点——但是有账号错误次数限制,爆破也不现实。
手机号那边也不能随便填,会提示账号不存在,说明是先校验了账号是否存在再做后续逻辑,这样爆破也没意义。
小结:登录框有次数限制 + 手机号存在性校验,暂时没有明显漏洞,换个方向。
三、主页信息收集
进入主页后,页面有图片和视频,右键查看源代码或者直接复制图片链接,能看到路径:
/upload/video/
/upload/image/这里就应该想到:既然有这些路径,那有没有对应的上传接口?
同时注意 URL,发现页面请求的文件都以.do结尾,这一般是 Struts2 框架的特征,记一下。
随意浏览了一下,只发现一个评论区,顺手测了个最简单的 XSS:
<script>alert(1)</script>页面上什么都没显示:
右键搜索也没找到自己写的内容,看起来有过滤,不急,先继续收集信息。
用 BP 登录后抓包,回显的却是 302 重定向:
猜测评论接口需要登录鉴权。因为用的是 BP 内置浏览器,没有登录的, 换成登录状态后发包,正常返回 200,但不管发什么内容都是固定回显:

没什么直接利用价值,先放着。
四、目录扫描——发现关键接口
用 Kali 的 Dirsearch扫了一下目录:
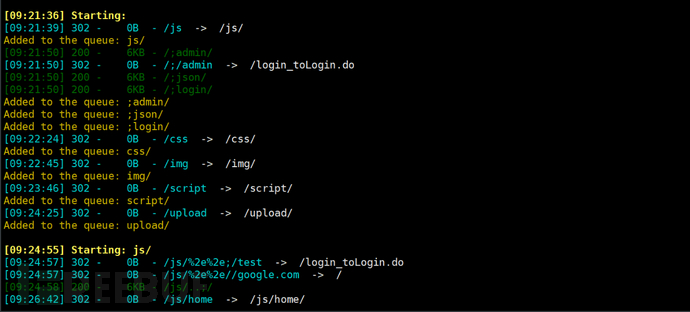
这里有重大发现,扫出了两个关键路径:
/;admin— Shiro 鉴权绕过路径/common/upload.do— 文件上传接口 (这里有点不记得了, 目录扫出来的还是js 代码里面找的)
/;admin这个是经典的 Shiro 鉴权绕过方式,利用的是中间件(Nginx/Tomcat)与 Shiro 框架对 URL 解析的差异(Normalized Path Error)导致的权限绕过,相关漏洞编号 CVE-2020-11989 或类似逻辑漏洞。
原理简述:Tomcat 会把
/;admin/xxx中的;admin当作 URL 参数部分处理,请求实际到达的路径是/xxx;但 Shiro 的路由匹配是在 URL 规范化之前做的,看到的路径里没有匹配到受保护规则,就放行了,从而实现绕过。
五、Shiro 鉴权绕过验证
直接用之前找到的评论接口来验证,先退出登录,然后构造:
POST /;admin/comment/saveComment.do HTTP/1.1参数保持和正常请求一致,浏览器退出登录,包里把 Cookie 全删了,点发包——返回 200。
经过多次测试,确认确实存在鉴权绕过。
六、后台目录探测
既然能绕过鉴权,自然想到直接访问后台。根据目录扫描的结果,测试了疑似后台的路径:
/login_toLogin.do返回结果全是空白页面,抓包发现是 302 重定向:
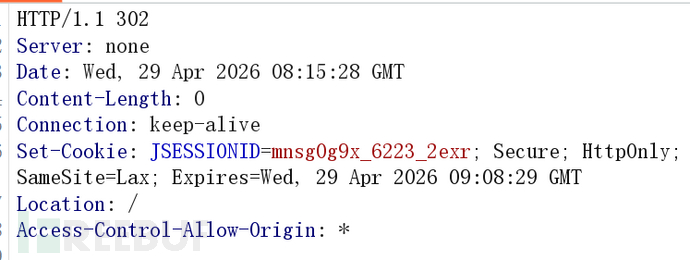
利用分号绕过,访问/;admin/login_toLogin.do,返回 200 但是"非法访问":
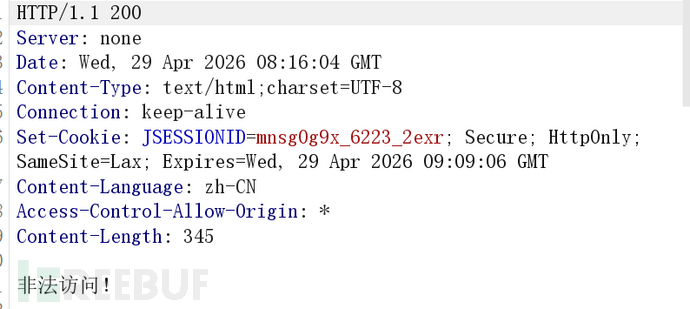
换成 POST 发包还是一样,看来是参数问题,但不知道具体参数名是什么,暂时放弃这条路。
思路:遇到这种情况可以考虑基于 HTTP 状态码差分分析做黑盒参数探测——对不同参数名/值逐一测试,通过响应差异推断后端逻辑。
七、上传接口黑盒测试
开始测试/common/upload.do。
直接 GET 访问,返回 405(Method Not Allowed):

换成 POST,返回 200 OK,但响应体里包着 500 异常。这种现象很典型——请求格式对了,但参数不对,服务端逻辑跑到一半报错了。
在 Java SpringMVC 框架里,后端接收文件通常用MultipartFile file参数,所以构造一个multipart/form-data请求:
POST /common/upload.do HTTP/1.1
Content-Type: multipart/form-data; boundary=----WebKitFormBoundaryCheckParam
Connection: keep-alive
------WebKitFormBoundaryCheckParam
Content-Disposition: form-data; name="file"; filename="test.txt"
Content-Type: text/plain
test_content
------WebKitFormBoundaryCheckParam--返回 200,但响应内容是:
{"info":"typeError"}翻译过来就是"类型错误"——说明文件格式有限制,但接口是通的。
经过测试,部分文件类型可以上传,比如.html、.pdf等,但.jsp这些不行。
换成 PDF 上传后,回显:
{"path":"/upload/null/20260429/test_423.pdf","fileNewName":"test_423.pdf"}直接访问这个路径,文件确实可以访问:
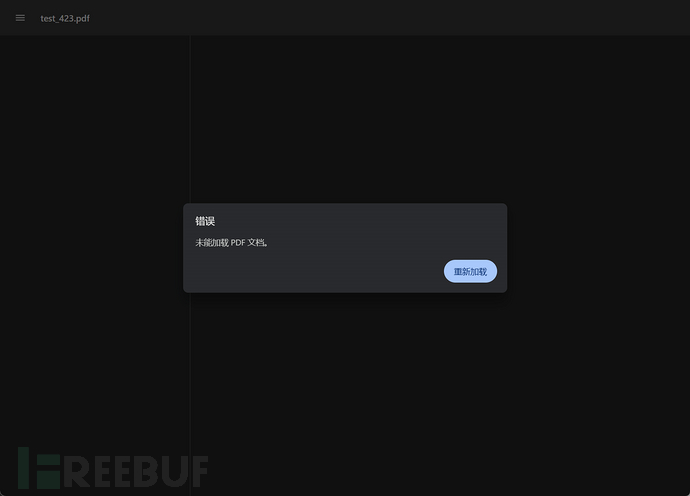
这里有个很有意思的细节——路径里有个null文件夹。
这说明后端在拼接路径的时候,代码逻辑大概是这样的:
savePath = "/upload/" + dir + "/" + date + "/" + filename;dir参数没有传,后端没有做空值处理,直接把null字符串拼进去了,这是路径变量未初始化导致的信息泄露,间接暴露了后端的代码逻辑结构。
八、路径穿越测试
既然路径是字符串拼接,自然想到测试路径穿越。
经过测试,参数名dir是可以被后端读取的,构造如下:
POST /common/upload.do HTTP/1.1
Content-Type: multipart/form-data; boundary=----WebKitFormBoundaryParamTest
Connection: keep-alive
------WebKitFormBoundaryParamTest
Content-Disposition: form-data; name="dir"
wrold
------WebKitFormBoundaryParamTest
Content-Disposition: form-data; name="file"; filename="test.pdf"
Content-Type: application/pdf
test_content
------WebKitFormBoundaryParamTest--返回:
{"path":"/upload/wrold/20260429/test_854.pdf","fileNewName":"test_854.pdf"}尝试路径穿越,把dir改成../:
{"path":"/upload/..//20260429/test_715.pdf","fileNewName":"test_715.pdf"}多级目录也没有过滤:
{"path":"/upload/../..//20260429/test_641.pdf","fileNewName":"test_641.pdf"}后端代码逻辑确实非常粗糙,直接做字符串拼接,完全没有做路径规范化校验:
savePath = root + dir + "/" + date + "/" + filename;标准修复方式:应该对
dir参数做白名单校验,或者使用Paths.get(root).resolve(dir).normalize()后校验结果是否仍在 root 目录内。
但问题是:.jsp及其各种变体(.jspx、.JSP等)全都被拦截了。试了试00截断,直接触发了 500 响应,而且 IP 还被封了。
看来这个系统代码写得不咋样,但是对危险操作的检测还挺严的。
九、XSS 利用与方向转换
目前能上传的只有.html,要么用来写钓鱼页面,要么做存储型 XSS。
写了个简单的测试页面:
<script>alert(document.cookie);</script>上传后访问,cookie 弹窗正常触发:
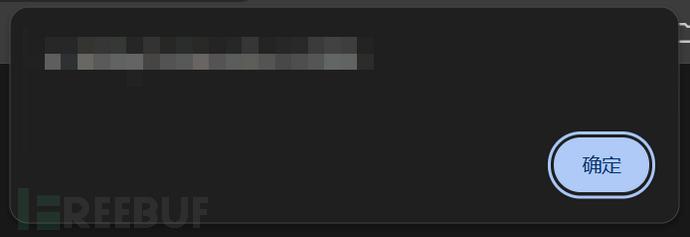
这个存储型 XSS 是确实存在的,但 Cookie 能不能利用还得看有没有HttpOnly,这里先记录,换个思路继续挖。
十、JS 接口挖掘(幻影插件)
换个方向,从 JS 代码里找接口。用的是幻影这个插件,做深度扫描:
扫出来的内容还挺多,还能导出 Excel,很方便。
十一、越权接口
在扫描结果里,找到了和评论功能相关的三个接口,经过测试,在未授权/越权状态下均可操作:
/comment/saveComment.do # 发表评论
/comment/getCommentTree.do # 获取评论树
/comment/delComment.do # 删除评论增删查都能越权,挺典型的 IDOR(Insecure Direct Object Reference)问题。
十二、Druid 监控台发现
后来 AI 提示我,既然/;admin可以绕过鉴权,那可以在这个前缀下再扫一次,针对性地加上后缀过滤:
dirsearch -u "https://目标/;admin/" -e do,jsp,xml,json,sql -x 404-e只看这些后缀,-x排除 404,这样结果会干净很多。
果然扫出来了 Druid 监控台:
/druid/index.html访问后需要账号密码:
去网上查了一下默认密码,对不上,暂时先放着。
Druid 监控台(
com.alibaba.druid)是 Java 应用常见的连接池监控组件,默认配置下可能暴露 SQL 查询记录、会话信息、接口调用统计等,是信息收集的好地方。默认密码一般是admin/admin或者druid/druid。
十三、Shiro 漏洞利用 & Getshell
Shiro 特征确认
/;admin越权本质上是 Shiro 的漏洞,虽然登录框没有"记住我"这种明显入口,但抓包发现部分回显包里有:
rememberMe=deleteMe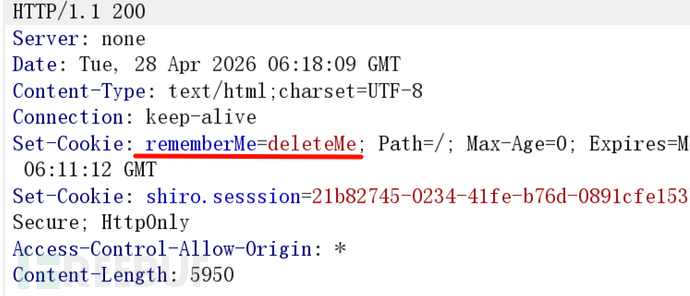
这就说明后端用了 Shiro,deleteMe是 Shiro 在认为 Cookie 无效时的固定回应,反而把自己暴露了。既然确认了 Shiro,那就顺着测一下反序列化。
Key 爆破
用的是 GitHub 上的工具:ShiroAttack2
直接填域名检测不到 Shiro,因为并不是所有页面都走 Shiro 鉴权,要找一个有鉴权的目录填进去,才能正常爆破。
但爆破的时候提示"未读取到可用于爆破的 Key 列表",应该是工具没找到字典,换了一个工具继续尝试,惊喜出现了:
[++] 找到 key:4AvVhmFLUs0KTA3Kprsdag==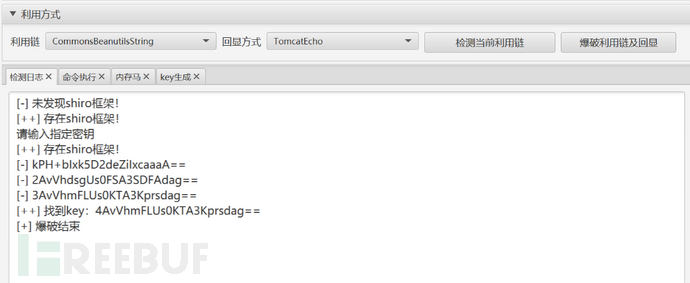
这个 Key 就是 Shiro 的rememberMeCookie 加解密密钥,很多系统用的默认密钥或者弱密钥,网上有现成字典。
链爆破
把密钥填回 ShiroAttack2,点击"全部链爆破"——结果全部失败。
刚准备自己用 URLDNS 链测一下的时候,AI 提醒我可能是 Cookie 的问题,一下就点醒我了,填上了一行正确的 Cookie 后再试:
CommonsBeanutils1(CB1)链成功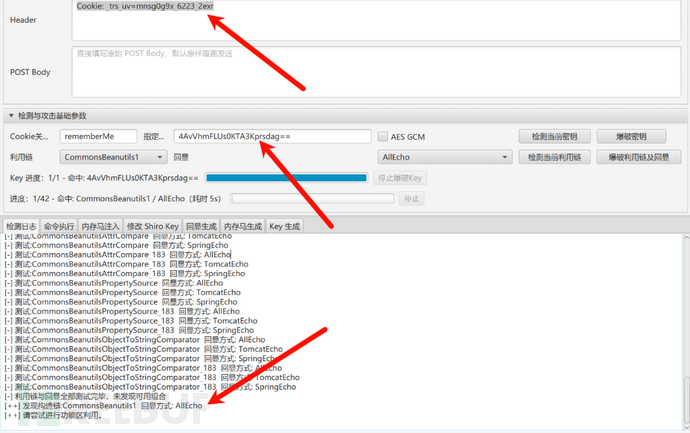
切换到命令执行界面,whoami、id、ifconfig一顿乱敲,完全没有问题,而且是 root 权限:
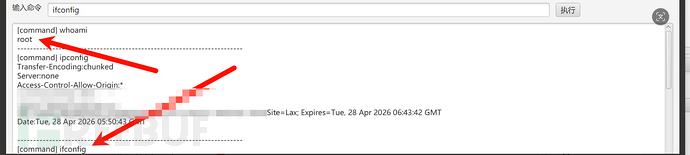
关于 CB1 链:
CommonsBeanutils1是利用commons-beanutils组件的反序列化链,不依赖commons-collections,在很多裁剪了 CC 依赖的环境里依然可用,是 Shiro 利用的高频链之一。这里 Cookie 问题指的是请求里的 Session Cookie 影响了服务端的反序列化处理逻辑,加上对应的认证 Cookie 后请求才能被正确路由。
十四、EDR 对抗与后渗透尝试
成功执行命令之后,发现目标有 168 和 10 两个网段,说不定有内网机器,想法很好,但执行起来很难。
内存马注入尝试
尝试了几个内存马注入方式,要么直接报错,要么立刻封我 IP,就没再继续了。用的一直是梯子,没钱用代理池,太难受了。
说明:当前命令回显也是通过反序列化注入的内存马实现的,不是真正的交互式终端,很多命令不支持,比如管道符之类的,危险命令还会直接触发 IP 封禁。
SSH 密钥植入尝试
想写 SSH 密钥来建立稳定连接,折腾了一顿,发现对方的 SSH 版本超级老,适配版本之后,又被 EDR 检测到了。
ps一看,竟然装了天融信或深信服的 EDR(记不太清了),反正很难缠。
EDR 检测原理:现代 EDR 不只看文件,还会监控进程行为、系统调用、网络连接等。SSH 密钥植入会触发文件写入 + sshd 重新读取 authorized_keys 的行为链,大概率被行为检测命中。
十五、数据库与配置文件读取
数据库连接尝试
ssh不行就看数据库,发现数据库和网站部署在同一目录下。尝试直接连接,被拦了;从自己机器连也被阻拦,出口防火墙策略很严。或许可以用反弹方式中转,但没有公网服务器,而且大概率依然会被封,就没继续了。
危险操作也不能随便测,虽然是授权的,但也不想搞破坏。
Druid 配置文件读取
想起来之前发现的 Druid,直接通过命令执行读配置文件:
cat /opt/xxx/tomcat/webapps/ROOT/WEB-INF/web.xml找到了 Druid 的账号密码,直接登录监控后台:
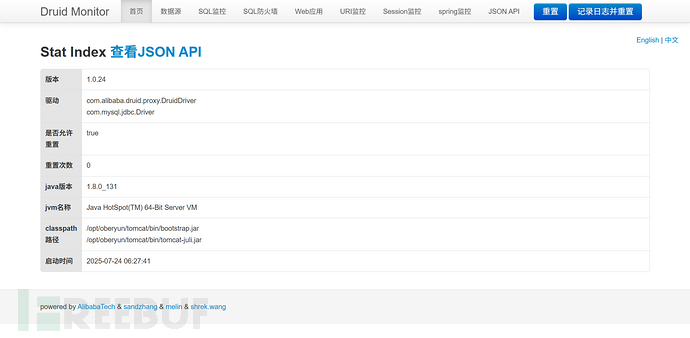
看了一下里面的内容,对于已经有命令执行权限的我来说,Druid 后台能给的信息价值相对就没那么大了。
历史命令 & 数据库配置
cat /root/.bash_history读了历史命令,发现了数据库配置文件路径,继续读:
cat /opt/xxx/tomcat/webapps/ROOT/WEB-INF/classes/dbconfig.properties数据库配置倒是拿到了,但连接不上,出口流量全被拦死了,暂时没有更好的办法。
到下午,测试就到此为止了,因为 EDR 的缘故后续基本很难继续推进。
十六、找cms漏洞
其实还找到一个文件上传的漏洞插件
思路就是拿到权限后简单看了一下文件和结构, 进过ai分析应该是有一个cms啥的类似的插件, 在网上搜一下历史漏洞, 果然有就是不知道能不能用, 抱着试一下的心态真的成功了
但是忘记了能不能解析jsp 来着, 应该还是不能的
总结
这次渗透的整体链路大概是这样的:
目录扫描 → 发现 /;admin(Shiro 鉴权绕过)+ /common/upload.do
↓
上传接口黑盒测试 → 路径穿越 + 类型限制(JSP 被拦)
↓
JS 接口挖掘 → 越权操作(评论 CRUD 全越权)
↓
发现 rememberMe=deleteMe → 确认 Shiro → Key 爆破成功
↓
CB1 链反序列化利用 → 命令执行(root)
↓
内存马注入失败(EDR 拦截)→ SSH 植入失败(EDR 拦截)→ 数据库连接失败(防火墙拦截)
↓
读配置文件 → Druid 后台登录 → 数据库配置读取(无法利用)几点体会:
URL 要时常关注,
.do后缀这种框架特征是很重要的信息,能帮助判断技术栈,进而找对应的历史漏洞。目录扫描不只扫一次,发现鉴权绕过路径(如
/;admin)之后,可以在这个路径前缀下再扫一轮,经常有意外收获,这次的 Druid 就是这么发现的。状态码差异是探针,GET 返回 405、POST 返回 200 包裹 500,这种组合就在告诉你"方法对了,参数不对",是黑盒测试里很常见的信号。
null路径是代码质量的泄露,响应里出现/upload/null/这种东西,直接说明后端字符串拼接没做空值保护,路径穿越测试优先级拉满。Shiro 的
rememberMe=deleteMe是个非常明显的特征,即使没有"记住我"的前端入口,抓包看响应头也能发现,这个特征出现了就一定要跟进测。链不对 Cookie 也不对,两个问题同时存在会让你完全摸不着头脑,这次 CB1 能成功很大程度上是因为 AI 提示了 Cookie 的问题,要不然可能就认为这个链不可用了。
在有 EDR 的环境里,文件落地类操作(写 Shell、植入 SSH 密钥)基本是死路,内存马是更优先的选择,但内存马注入本身也有行为特征,整体难度上了一个台阶。